浏览器输入URL到获取网页的过程
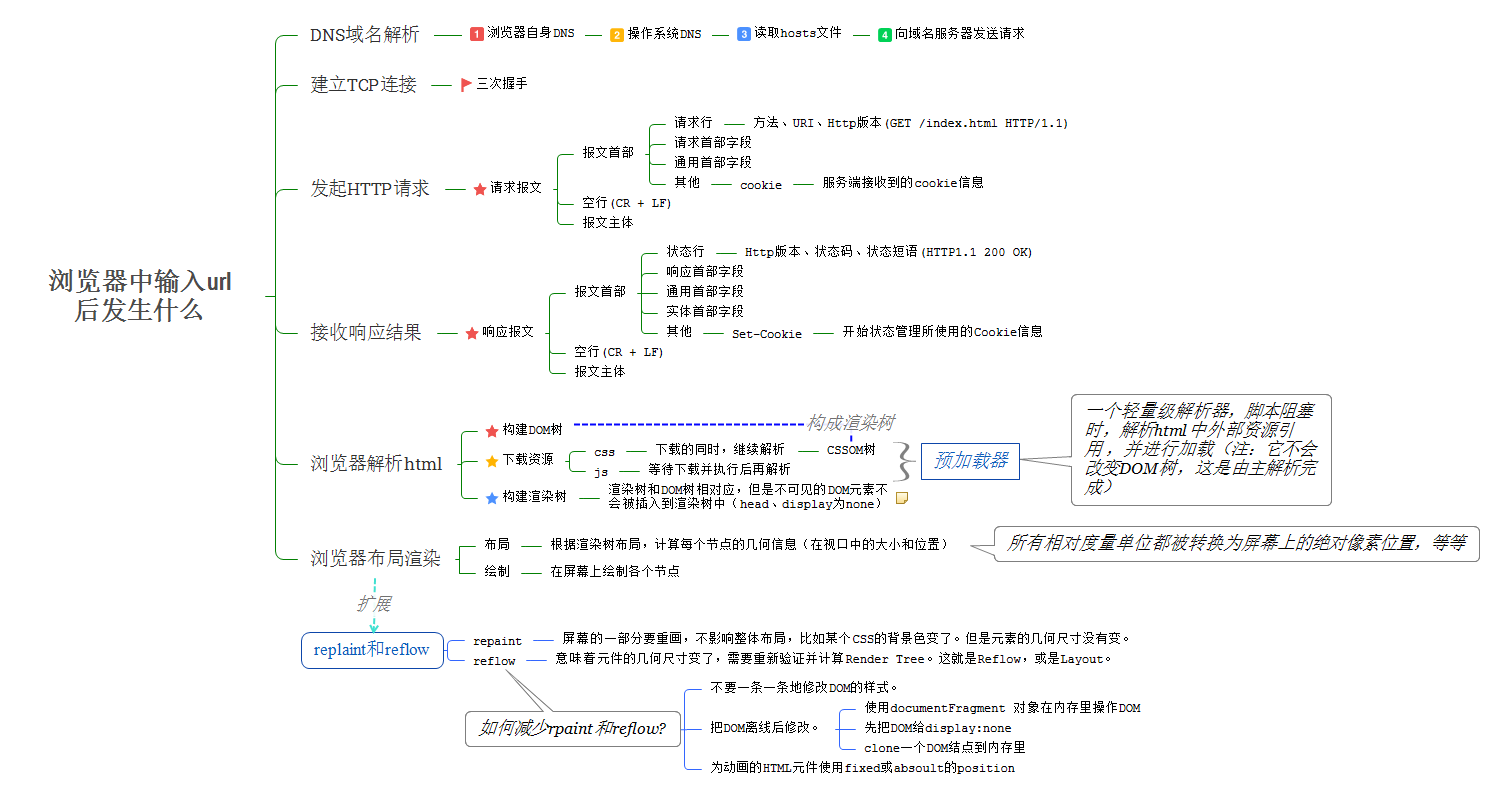
上面这张图大致描述了浏览器输入URL之后发生了什么。下面梳理一下详细的流程。
在条件是:
- 一个Chrome浏览器
- 一台Linux服务器
- 发起HTML请求
- 不考虑缓存和优化
- 采用HTTP/1.1+TLS/1.2+TCP协议
从浏览器输入URL地址
URL也叫做统一资源定位符,描述了特定服务器上某个资源特定的位置,URL包括三个部分:
- scheme描述访问资源使用的协议
- 服务器的因特网地址
- 其余部分指定了web服务器的某个资源
一个有效的URL
1 | http://video.google.com.uk:80/videoplay?docid=-7246927612831078230&hl=en#00h02m30s |
上述网址分解为:
- 传输协议:http,类似还有https,ftp,etc
- 主机或者主机名:video.google.com.uk
- 子域名是:video
- 域名是google.co.uk
- 顶级域名:uk
- 二级域名:com.uk
- 端口号:80(http协议的默认端口)
- 路径:表示web服务器上一个资源的位置
查询过程:
- 首先会查询浏览器的缓存,浏览器会存储一定时间内的DNS记录
- 如果没有找到,操作系统缓存中查询;
- 路由器也会由DNS记录,继续在路由器缓存中查询;
- ISP互联网供应商中查询,这里是接入internet的中继站
- 最后在DNS系统上查找;
DNS解析过程
DNS采用迭代查询和递归查询两种方式,因为IP地址难以记忆,所以域名帮助我们记住网址,域名实际上并不能找到服务器的位置,而是要将域名通过DNS服务器解析为ip地址之后再去确定服务器的位置。
首先浏览器像本地DNS服务器发送请求,如果本地的DNS地址未查询到,需要采用递归和迭代的方式依次向根域名服务器,顶级域名服务器,权威域名服务器发送查询请求,知道找到一个或者一组ip地址,返回给浏览器。
DNS本身的传输协议是UDP协议,但是每一次迭代和递归查找是很耗时的,所以DNS存在这多级缓存,
缓存分为:浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。
DNS负载均衡
DNS每一次不一定会返回一个同一个服务器的地址,DNS可以返回一个合适的机器的IP,根据每台机器的负载量,机器的物理位置等合理分配。CDN技术就是利用DNS的重定向技术返回一个离用户最近的服务器。
TCP连接
建立TCP连接,经典的三次握手过程。
TCP是一个端到端的可靠的面向连接的协议,所以HTTP基于传输层协议不用担心数据的传输问题。
发起HTTP请求
请求方法:
- GET:获取资源
- POST:传输实体主体
- HEAD:获取报文首部
- PUT:传输文件
- DELETE:删除文件
- OPTIONS:询问支持的方法
- TRACE:追踪路径
建立安全的加密信道之后,浏览器开始发送http请求,请求报文由请求行,请求头,空行,实体组成。请求头由 通用首部,请求首部,实体首部,扩展首部组成。
返回HTTP响应
接受响应结果,详细的HTTP状态码如下:
最后到内容到浏览器,浏览器开始解析html和加载渲染。